
Swapping bits and distributing hashes on the decentralized web
How IPFS peers find, request, and retrieve content (and each other) on the decentralized web
If you’ve been following our blog at all, you’ve probably come across concepts like interacting with the IPFS network, or communicating between IPFS peers, or even read out blog post about how IPFS peer nodes identify each other on the distributed web. But for the most part, we haven’t totally defined what we mean when we make these types of statements. For instance, what types of interactions are peers engaging in? How is information exchanged? To what extent do they advertise content they are hosting, and how do they request new content, etc?
What we have covered, is how peers use their PeerID (hash of their public key) to identify each other (see this post for some technical details), and that we can get and add content to the IPFS network as IPLD DAG objects. So the logical next step for our blog is to cover exactly how IPFS peers find, request, and retrieve content (and each other) on the decentralized web…
Distributed hash tables
First things first: when we say things like “query the network”, “ask the network”, or “get it from the network”, what we’re really saying is “query the distributed hash table”. So firstly, a hash table is a data structure that stores information as key/value pairs. Think of a Python dict, or a Javascript object, or a document-based database. Similarly, a distributed hash table, or DHT, is a hash table where the data is spread across a network of nodes or peers. And these peers are all coordinated to enable efficient access and lookup between nodes. Obviously in a decentralized system, we need something like this to help peers discover each other, and content. A DHT is nice because we have a decentralized, fault tolerant (and scalable) data structure. Our peers don’t require centralized coordination (each peer really only knows about a smallish part of the network), and through smart redundancy, the system functions even when nodes fail or leave the network. Finally, because no one peer has to know about all keys, the system scales quiet nicely, and can actually accommodate millions of peers.
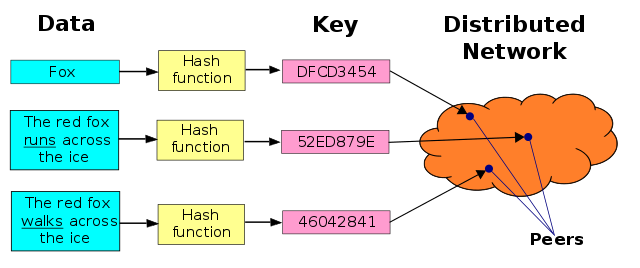
IPFS uses a DHT to support routing and discovery of content and peers on the network. In other words, things like who has what, where are they, how to get it, etc. In practice, IPFS uses the hash (CID) over the content as the key in the DHT key-value store. So if you ask for some hash, your peer will lookup in DHT which peers have that content, and start routing their data to you. The DHT used by IPFS — for those who are interested — is based on Kademlia, which is pretty common is p2p systems. We won’t go into details here quite yet, but we will explore the IPFS DHT a little bit…
Normally, when accessing and sharing content on IPFS, we’d use the high-level add, get, and cat tools. But we can also query the DHT directly if we want. For instance, let’s find peers that can provide a particular bit of content.
ipfs dht findprovs QmW2WQi7j6c7UgJTarActp7tDNikE4B2qXtFCfLPdsgaTQWhile we’re at it, we can also find out ‘where’ those peers are, for routing purposes (this can be a bit slow when manually choosing a peer, but try picking one from the list generated from the previous command). This will retrieve the address (as a multiaddress) of the peer(s) to help us retrieve the file (well, help our peer find it, we don’t ever need to do this manually).
ipfs dht findpeer QmPEGLxDUAYTSLFoRS88T5qsFEsAhcERicDkiEL5oA2yS5Ok, so now that we know that the distributed hash table is used to find (query) peers and content on the IPFS network, let’s discuss how content is actually requested and retrieved.
Bitswap
You may have seen IPFS described as something like BitTorrent mixed with Git, or something to that effect. The BitTorrent piece comes from how blocks of data are exchanged and requested over the IPFS network. IPFS actually does things a little bit differently (get it 😉), so they have their own exchange protocol, which they call Bitswap. Bitswap is the data trading module for IPFS. Its purpose is to request blocks from, and send blocks to, other peers in the network. And that’s pretty much it.
Bitswap has two primary jobs: 1) Attempt to acquire blocks from the network that have been requested by the client peer (your local peer) and 2) judiciously (though strategically) send blocks of data that it already has in its possession to other peers who want those blocks. Easy.
The version of Bitswap we use now is still a bit of a work-in-process, but it works great already. It is actually based on a relatively simple message-based protocol, where all messages contain wantlists or blocks of data. Basically, when a peer receives a wantlist from a fellow peer, that peer needs to decide if they want to send over the requested blocks (obviously it checks if it has them first), and then the other peer, upon receiving those blocks, needs to then send out a Cancel notification signifying they no longer need a given block. This sounds pretty straight-forward, but there is a lot of complexity baked in… because like in a BitTorrent swarm, a bitswapping peer has to have strategies for deciding when and to whom to send blocks of data. Otherwise, we’d get leeches, and unfair exchange practices on the network.
Give and take
If you recall from our previous post on exactly what happens when you add content to IPFS, raw data added to IPFS is actually chunked up into many (smaller) blocks of data, about 256k each. For small files, obviously no chunking happens. These chunks, or blocks, are what get shared with Bitswap. The key difference here from say BitTorrent, is that unlike in BitTorrent where blocks being exchanged are all from a single torrent (a single file usually), on IPFS we basically have one big swarm, so peers can pull blocks from just about any peer who has them. The structure of the IPFS network and the actual DHT algorithm (see above) that is used makes this possible.
On top of this, we have a very complex ‘dance’ between peers, with the block exchange essentially modelled as a marketplace for exchanging data. Each peer participating in this marketplace has an internal strategy that they use to decide if they will exchange content (and other information) with any other peer they are contented to. These strategies are not necessarily fixed, and can be designed to do things like incentivise data duplication, or uptime, or punish leechers, or whatever. In fact, in the future, the IPFS network will likely support a whole range of arbitrary Strategies. They could even be based on a bartering system based on a virtual currency, such as FileCoin…
FileCoin
FileCoin has been covered lots elsewhere, so we won’t dwell on this topic too much here, but… if you aren’t already aware of FileCoin, it is Protocol Labs’ (the group behind IPFS) cryptocoin. The FileCoin system is a decentralized market for taking advantage of unused hard-drive storage space, and while their ICO has already come and gone, they are quickly moving towards a working testnet so that developers can start to test applications on top of this decentralized system. Check out their recent update to learn more about their latest progress.
The basic idea is that FileCoin allows anyone to participate as a storage provider (rather than just folks like Dropbox or Amazon, etc). It also allows miners to compete on things other than just cost, like reputation and reliability, data availability, etc. Once it is up and running, it will do some important things, the most important being that it will be designed to incentivise strong end-to-end encryption, cryptographic erasure (so things will be cryptographically deleted when needed), and more. The folks behind FileCoin are hoping it will lead to increased competition for storage space, and that hopefully everyone will benefit in this type of market-driven system.
FileCoin relies on two ‘proofs’ like most other crypto coin systems. Except, unlike say Bitcoin, who’s proof-of-work protocol kind just wastes energy, FileCoin’s proof-of-replication will actually be used to accomplish useful things (like prove that your data is safely stored somewhere and is accessible). So we have proof-of-replication, which is used to prove that any replica of data is stored in physically independent storage. In other words, that someone has actually stored your data for real. And we have proof-of-space-time which — besides being to coolest sounding proof ever — is used to prove that some data was being stored throughout a period of time. For instance, if you are paying someone to keep your precious photo backup for you, you want to be sure they’ve been storing it the whole time you were paying them for it, and not just periodically or not at all!
Ok, so obviously three paragraphs is not enough to explain a complex, game theoretic-based marketplace for buying and selling digital storage… but hopefully you get the idea. Really, you should just watch this video, which gives a much better picture of how IPFS and Filecoin fit together:
Learning by doing
So Bitswap and the ideas around a data exchange marketplace were actually presented in the original IPFS whitepaper, which you should certianly check out for yourself. However, while you’re at it, you might also want to take a look at this series on demystifying that paper a bit. In any case, in the white paper, the authors talk about how DHT and BitSwap allow IPFS to form a massive peer- to-peer system for storing and distributing blocks quickly and robustly. This is really buge piece of the IPFS puzzle, so let’s explore these two protocols in some more detail.
The DHT and BitSwap allow IPFS to form a massive peer- to-peer system for storing and distributing blocks quickly and robustly.
Ok, so recal from earlier that the DHT is essentially the routing layer of IPFS. Its primary purpose in this peer-to-peer system is to 1) announce that node has some data, and/or 2) find out which nodes have some specific data or content (via its multihash). If the data itself is pretty small (so less than 1k) we can actually store this data as a value directly in the DHT. For larger values (so pretty much everything else) we actually just store references to the data. In the case of IPFS, we store PeerIDs of nodes who can serve up the content. Nice and simple right?
So that’s DHT stuff, what about Bitswap? Well, as always, there’s a command for that™️ second piece of the IPFS puzzle. To see it in action though, we’ll need to be in the middle of a data request/exchange dance. So we might want to request a very large file, so we can see what’s happening while the bits are swapping and the downloads are happening.
So first, go ahead and query your bitswap wantlist. Right now, this should be empty, because we aren’t in the middle of requesting anything. Let’s change that.
ipfs bitswap wantlistNext, open a separate terminal, and get a large file from the network. Here we have the classic Big Buck Bunny video, which you can also ‘stream’ over IPFS at that link.
ipfs get QmdpAidwAsBGptFB3b6A9Pyi5coEbgjHrL3K2Qrsutmj9KOk, while that’s happening, jump back to your original terminal, and start running your wantlist query again.
ipfs bitswap wantlistYou’ll see multiple hashes that are being requested from the network. The cool thing here is that your peer doesn’t care where these blocks are being pulled from, just that they are being requested and pulled as needed. Cool right?!
Who’s helping us?
So once that entire video has been downloaded, we might be able to use the DHT to find peers that can provide it (and that we likely pulled from). Sometimes this command can be slow when done manually, so don’t sweat it if it doesn’t seem to be working.
ipfs dht findprovs QmdpAidwAsBGptFB3b6A9Pyi5coEbgjHrL3K2Qrsutmj9KAdditionally, we can pick a peer from the returned list, and try to see if you have downloaded any data from that peer. Here’s my Peer ID, so you could see if you pulled anything from me while downloading the bunny video (I’m pinning it right now, so you very well might have). If you have, there should be evidence of that there.
ipfs bitswap ledger QmWYswt2hjxUjJFGyNXBfsoZnAbXMsoPazseZSncwFPv9eAnd of course, what we’re actually exchanging between peers are blocks of data. So we can explore one of the blocks from our wantlists from before to see what they look like.
ipfs block stat QmeuYiYh7gJG4tvN7dXY9wgk5i6rpWQGGrMPJW8pognpveHere’s 👇 the stats for one of the blocks that showed up in my wantlist. Very fun indeed!
Key: QmeuYiYh7gJG4tvN7dXY9wgk5i6rpWQGGrMPJW8pognpve
Size: 106914And that just about rounds it all up folks. You now know pretty much everything you’d want to know about swapping bits and distributing hashes on the IPFS network. Couple this with our previous post on adding content to IPFS, and you should now have a pretty decent grasp of what is going on under the hood when you access the decentralized web with IPFS. If you want to learn even more about IPFS, the decentralized web in general, and how Textile is reinventing our mobile experiences in a decentralized and secure way, why not check out some of our other stories, or sign up for our Textile Photos waitlist. While you’re at it, hit us up on Twitter and tell us what cool distributed web projects you’re working on — we’d love to hear about it!
