
Objective
We aim to build a collection of modules, together called the Powergate that allows any application (such as a pinning service) to use a robust set of underlying technologies and APIs that should make building on the Filecoin network simple.
Update: This document reflects our thinking early in the development process. Objectives and general functionality is the same, but exact connections and architecture is changing as we learn. We recommend you explore the Powergate project repository for the latest thinking.
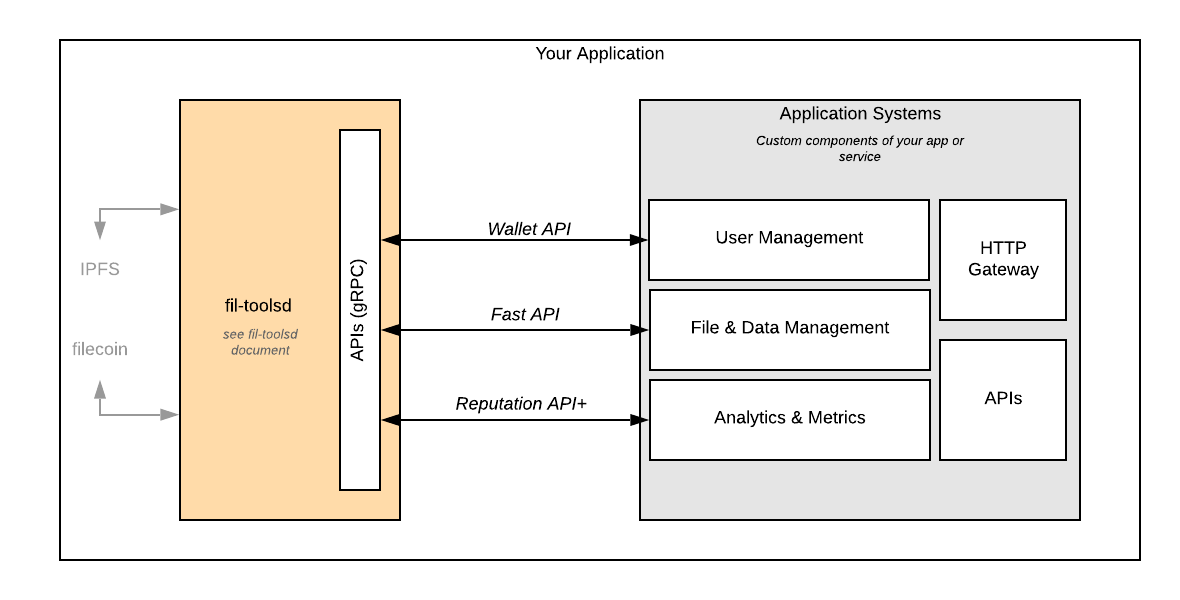
We make Powergate and the modules it contains available in an open-source repository for any project to use. Additionally, we provide,
- Docker images for running the system in your own infrastructure easily.
- A
powbinary for running the system directly. - A CLI tool for interacting with and testing your system.
- Analytics, administrator dashboards, and data feeds so you can monitor the system internally and expose advanced data to your users.
For an overview of the project, please read our blog post. Briefly, our design objectives are:
- Make it fast to store and retrieve data from the Filecoin network.
- Make it familiar to developers who have used IPFS or traditional storage services.
- Make it seamless for a developer using IPFS to connect & integrate Filecoin with existing IPFS projects.
- Make it easy to adopt, including minimal setup or tutorial steps to start using Filecoin.
Target Audience
- Pinning services. These services already have user management systems, including quotas, payment methods, and authentication. Here, the Powergate can help them quickly attach that existing system to Filecoin and run custom APIs that map users to unique Filecoin wallet addresses and then use those address for deals, retrieval and more.
- End-user applications. These are projects that wish to expose Filecoin systems to a set of users, potentially assisting with wallet generation & management, deal monitoring, deal renewal & repair, and more.
- Filecoin developer community. These developers and projects may have their own, very custom, systems built on Filecoin. Still, they can augment their work with specific components of the Powergate project (e.g., Deal Module or Repair Module) or potentially subscribe to data feeds such as the Reputation Index.
Progress Updates
- https://blog.textile.io/filecoin-tools-progress-update-09-march/
- https://blog.textile.io/filecoin-tools-progress-update-24-february/
- https://blog.textile.io/filecoin-tools-progress-update-10-february/
- https://blog.textile.io/filecoin-tools-progress-update-27-january/
- https://blog.textile.io/filecoin-tools-progress-update-13-january/
FAQ
When a user stores data, how do they set the price for the deals?
Depending on the system running filtools, there are different ways to choose the price of your storage deals. First, interactive interfaces can request bids from storage miners without any bounds and allow the user to interactively select the deal that suits their needs. Second, users can provide a config or single use parameters that set bounds on maximum price, filtools will then try to select the best miner according to those configuration choices.
Can systems running filtools bring their own IPFS nodes?
Yes. The system relies on access to an IPFS node via the HTTP API. This means that you can provide any configuration of IPFS nodes as long as you can give filtools access to the HTTP API for getting from and adding to the network.
Design and Architecture
The Powergate (pow) binary contains all the modules. The following is a design diagram of pow binary:
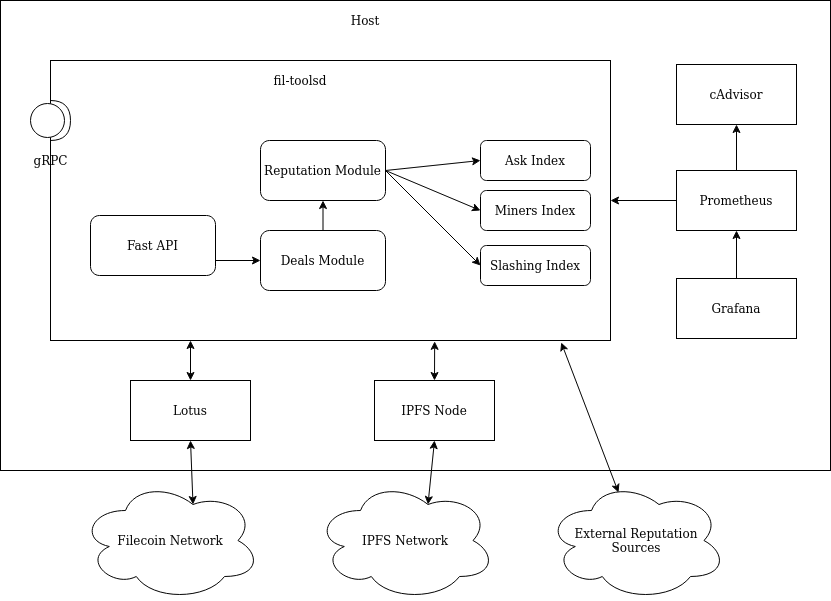
Notes:
- The Powergate and
lotuscommunicate via Lotus APIs. - The Powergate and
ipfscommunicate via IPFS API. Prometheususes a standard prometheus-http endpoint.- Arrows are conceptual, there might be more interactions not described in the diagram.
Internal gRPC APIs
Generally, all APIs provided by the Powergate (including all modules) are defined using the gRPC system. The APIs use protocol buffers to define data types exchanged through the API. The benefits of the internal gRPC APIs are that APIs are typed, and all APIs and the types they use are versioned. For applications (including CLIs and end-user applications), gRPC APIs can be used to back more human user-friendly interfaces and APIs.
Components: System Metrics & Analytics
System-wide Metrics
All modules are designed to report metrics, which gets registered, aggregated, and displayed using the following libraries/subsystems:
- Opencensus for registering metrics.
- Prometheus for metrics scrapping.
- Grafana for health dashboard of Prometheus metrics.
- cAdvisor for container metrics if run in Docker.
A Grafana dashboard is maintained to provide easy to understand metric-views to understand the health of the server. Additionally, a pprof endpoint can be enabled for live-profiling data of the Golang process.
Components: Network Indices
Ask Index
This component stores information about asks in the Filecoin Network. Its main goal is to provide cached access to storage deals from miners.
For a configured interval, this component has the following workflow:
- Ask Lotus a list of all miners
- It QueryAsk each miner to provide up-to-date information of Storage Ask
- Save this information.
Note: this is a full-scan algorithm since there’s no other possibility. If any better system such as pubsub or similar is available, this can be changed. Currently, since there are few miners, this method is quite fast (considering it does capped-concurrent work).
This component can run independently, register metrics, and isn’t corrupted on-chain reorgs. This index provides public methods to get current index state, and gRPC and HTTP endpoints for external information access. Finer-grained queries might enhance DX.
Development Status:
- Initial version complete
Miner Index
The Miner Index stores up-to-date information about miners. Information is separated into two groups: on-chain and metadata.
On-chain information refers to information stored on-chain. Currently, the following information is stored:
- Miner current power
- Miner current relative power
Any other on-chain information can easily be added since all necessary interaction with on-chain tracking is working. The cost of adding more information should be calling new APIs. Clients can fetch the current state of the index. More fine-grained APIs for querying data can be made.
Metadata information is information that doesn’t live on-chain or might get updated at a different rate than chain growth. Currently, the following information is stored:
- Online attribute being true if the miner is considered online.
- UserAgent which refers to reported lotus version running.
- Location information including country, latitude, and longitude.
All this information is gathered by using the on-chain index as the miner discovery mechanism. The Powergate is running a libp2p host, which is configured to connect to the Filecoin Network. This host is configured to use the custom DHT protocol tag and boostraping to the same peers as Lotus. All information in the index is gathered by querying the DHT for addresses of miners, using the ping protocol to determine liveness, and using an offline-database to map IP addresses to locations.
This component can run independently, register metrics, and information isn’t corrupted on chain reorgs. This index provides public methods to get current index state, and gRPC and http endpoints for external information access. Finer-grained queries might enhance DX.
Development Status:
- Initial version complete
Slashing Index
The Slashing Index stores historical information about slashing events of miners. It inspects the chain on every new tipset to detect a change in the SlashedAt attribute in the Miner Actor. Since this attribute may change on every new tipset, this components builds a history of all values that existed. Hence, building a slashing-height history information of each miner.
This component can run independently, register metrics, and information isn’t corrupted in chain reorgs.
Development Status:
- Initial version complete
Components: Filecoin Modules
Reputation Module
The Reputation Module's main goal is to aggregate all known information about miners to construct a rank. To calculate a score for each miner, it considers information from different sources:
- Ask Index
- Miners Index
- Slashing Index
- External Sources (not yet implemented)
Every time a source reports having updated information, the rank is rebuilt. The current implementation is a weighted average of indexes information to come up with a meaningful score. e.g., having high relative power is considered positive, the # of times that miner was slashed is considered exponentially negative, Storage Ask prices below the median of the market are considered positive, etc.
Having easy access to multiple sources of information might fire the imagination to build more complex ranks or different scoring algorithms.
This module provides a public method to get the top N miners from the built rank, the current index state, and gRPC and HTTP endpoints for external information access. Finer-grained queries might enhance DX.
Development Status:
- Initial version complete
- gRPC API available
- CLI available
- Public feeds in development
Deals Module
The main goal of this component is to enable richer features for making deals. The client-side features include:
- Storing data using a specified configuration.
- Watching how deals are unfolding from Proposed to Active on-chain.
- Retrieving data.
Given data and a configuration for storage, the module will execute a storage deal. Configuration parameters involve:
- Store data replicated in a received list of miners, or let them be selected automatically using the Reputation Module.
- Apply an erasure-coding data transformation to the original data, and store sliced pieces of the output in multiple miners.
The data can be indicated by:
- Raw bytes to be stored as-is.
- CID of IPLD graph to be fetched. If this is the case, the data is transformed to the car format, which will be the target to be stored.
Note: CID fetching could potentially accept an IPLD selector to fetch it partially.
Note: the current implementation is partial complete due to the impossibility of making and retrieving data in Lotus Testnet. Recent efforts have been made to run e2e Deals creation and retrieval in a customized Lotus Devnet, since the current Local Devnet setup is designed for testing mining-hardware. This new tool allows building advanced features for the module.
Development Status:
- Initial version complete
- gRPC APIs available
- CLI available
Fast API Module
The Fast API provides fast storing and retrieval APIs for data. Each client using this module will have a dedicated instance of the component since different clients can configure them differently.
Any request received for an operation will carry a token which:
- It is checked not being expired or invalidated.
- It determines which instance of Fast API the operation will be done and thus determines default configurations for each layer of storage.
An instance state includes:
- An ID that uniquely identifies the instance.
- Information about currently stored data.
- A log of all operations done through the API.
- Wallet address to be used in Lotus node for storage or retrieval operations.
Whenever a store or retrieve operation is performed, it is processed in a pipeline of different types of storage. Each layer provides different order of magnitudes for executing the operation:
- RAM
- IPFS Cluster
- IPFS public network
- Filecoin
A storing (Store()) operation includes:
- CID of the data to be stored retrievable on the IPFS network, or direct raw data in API call.
- Configuration, which includes:
- Filecoin Config: include the replication configuration to be used.
- Storage type: hot or cold
The storage types are defined as:
- Hot: all layers of storage will be used to store data; this allows fast retrieval. An additional parameter specifies the batching time for the stored data. This duration is the amount of time for a CID to be in hot-layers until being pushed to Filecoin storage.
- Cold: only using the Filecoin layer.
All decisions regarding miner selection will be done automatically. After a storage operation is executed, it can be referenced later to change its configuration (Transition()).
A retrieval (Retrieve()) operation is done by CID and it will try to fetch the data from Hot layers if available. If Hot data isn't available, it will ultimately fetch the data from Filecoin network. When the Filecoin retrieval completes, the data will move to hotter layers. The retrieval operation can specify only to try fetching the data if available in Hot-layers, and failing if that isn’t the case to avoid incurring in costs.
A remove (Remove()) operation for a CID removes storage in all layers. Note: In particular, in the Filecoin layer, it isn’t clear if this can be possible (cancelling a deal, may be possible if both parties accept).
An information (Information()) will output instance state such as:
- Active data stored with it’s corresponding configuration.
- Instance operations log.
- Wallet address and balance.
This module also has repair capabilities to watch for stored data and executing best-effort operations to ensure that the original storing configuration holds.
A typical user-flow for an API call would be the following:
- A storage API call is received from a client.
- Auth token for the call is checked. If invalid, expired, or invalidated, the request is cancelled. If valid, continue.
- The auth-token information defines the logical instance of the Fast API to be used, and thus its state. Or said differently, which Fast API instance ID it maps to.
- The operation to be executed created in the instance log.
- The corresponding operation is executed.
- The entry of the instance log is changed to state ok or error depending on the previous step output.
Development Status:
- Initial version in development
Get involved
We are looking for use-cases and developer feedback. If you'd like to get involved, send us an email or join our Slack channel.